C# API to Zip S3 files
S3 doesn’t have a built in service to provide an Zip Archive of a set of files held in S3, you need to implement your own.
There appears to be two main ways to do this, either Pre-zip the files and store in S3 or do it on the fly.
I chose the later approach and created a working version in C#, but was not happy with the implementation and so decided to revist it to improve the solution.
The first attempt
The initial code looked something like this:
- API exposes a CreateZip method which has a list of file Ids passed to it.
- The method creates an archive held in a memory stream.
- Each Id is used to read the file details from a database.
- Each file is downloaded from S3 into a memory stream and added to the Archive.
- The archive is returned to the caller as a File stream.
[HttpGet]
public async Task DownloadZip(List mediaIds)
{
var zipStream = new MemoryStream();
using (var zip = new ZipArchive(zipStream, ZipArchiveMode.Create, true))
{
foreach (var id in mediaIds)
{
var media = await GetMediaInfoFromDB(id);
var fileMemoryStream = await DownloadS3FileAsync(media);
var entry = zip.CreateEntry(media.Name);
using var entryStream = entry.Open();
fileMemoryStream.CopyTo(entryStream); // add the file to the archive
}
}
zipStream.Position = 0;
return File(zipStream, "application/octet-stream"); // return a filestream of the archive.
}
public async Task DownloadS3FileAsync(string path)
{
using (var client = CreateS3Client())
{
var request = new GetObjectRequest { BucketName = _bucketname, Key = path };
using (var getObjectResponse = await client.GetObjectAsync(request))
{
using (var responseStream = getObjectResponse.ResponseStream)
{
var stream = new MemoryStream();
await responseStream.CopyToAsync(stream, ct);
stream.Position = 0;
return stream;
}
}
}
}
However, it is not perfect and may not be suitable for some use cases. So how is this solution flawed?
Before a response can be sent to the user, all files must be read into the archive. This will delay the response being sent to the user. Is this a problem? This depends on your use case and the size of the archive, but an earlier response is probably better.
As a result, the Zip memory stream will require the same amount of memory as all archived files. When your files are small, then it won’t matter, but if your files add up to a few GB or more, then it may be a problem, especially if you are using a machine with limited memory, such as a 128MB Lambda.
Each file downloaded from S3 is copied into memory, which requires space. Using small files is not a problem, but if a file is 1GB, then using that much memory may be difficult.
The goals for the improved scaleable solution:
- Make the final archive take up less memory
- Respond faster to the user.
- Make each S3 file take up less memoory.
A bit of Googling allows me to build on the work of others…
The first solution I find is written in Node: https://dev.to/lineup-ninja/zip-files-on-s3-with-aws-lambda-and-node-1nm1, it zips up files from S3 and returns a zip to the user, it solves the problem of memory size by using streams and the notion of a pass through, so I need something like this in C#.
After a bit more googling I find https://swimburger.net/blog/dotnet/create-zip-files-on-http-request-without-intermediate-files-using-aspdotnet-mvc-razor-pages-and-endpoints , he is zipping local files so nothing to do with S3, but this blog adds an important piece to the puzzle.
Initially he starts by returning a FileStream just like the above solution:
return File(zipFileMemoryStream, “application/octet-stream”, “Bots.zip”);
But after some advice from David Fowler (an architect at Microsoft), you can use a pipeline to return data from a stream as it is written to the client. You do this by passing Response.BodyWriter.AsStream() into your archive constructor to replace the memory stream, this means that the whole archive is not stored in memory, as soon as the archive starts to be written, this data is sent to the user which improves response time. This solves our first two goals.
using (ZipArchive archive = new ZipArchive(Response.BodyWriter.AsStream(), ZipArchiveMode.Create))
Now we need to make each S3 file use less memory. If for example a file was 1Gb in size we don’t want to have to download it all before adding it to the archive. The ZipArchive entry gives us a Stream to write to and we currently use a MemoryStream to copyTo it. What we need is an S3 Stream and this is provided by the ResponseStream in the result of client.GetObjectAsync(request). In our original version we were copying this into memory, this looks like it was unnessary.
The final version
The file I am using “movie.mpg” in this example is 1GB in size and shows what happens when a large file is part of the zip, normally the list of files would obviously be a lot larger.
Note: I have set the compression to none as all the media is already compressed.
Our rewritten code would look something like this:
[HttpGet]
public async Task ZipAFileS3()
{
var s3Keys = new List { $"media/movie.mpg"};
var bucketname = "myBucket";
Response.ContentType = "application/octet-stream";
Response.Headers.Add("Content-Disposition", "attachment; filename=\"files.zip\"");
using (var s3 = CreateS3Client())
{
using (var archive = new ZipArchive(Response.BodyWriter.AsStream(), ZipArchiveMode.Create))
{
foreach (var s3Key in s3Keys)
{
var entry = archive.CreateEntry(Path.GetFileName(s3Key), CompressionLevel.NoCompression);
using (var entryStream = entry.Open())
{
var request = new GetObjectRequest { BucketName = bucketname, Key = s3Key };
using (var getObjectResponse = await s3.GetObjectAsync(request))
{
await getObjectResponse.ResponseStream.CopyToAsync(entryStream);
}
}
}
}
}
}
public static AmazonS3Client CreateS3Client()
{
var AWSAccessKeyId = "";
var AWSSecretAccessKey = "";
var Token = "";
var awsCredentials = new SessionAWSCredentials(AWSAccessKeyId, AWSSecretAccessKey, Token);
return new AmazonS3Client(awsCredentials, RegionEndpoint.EUWest1);
}
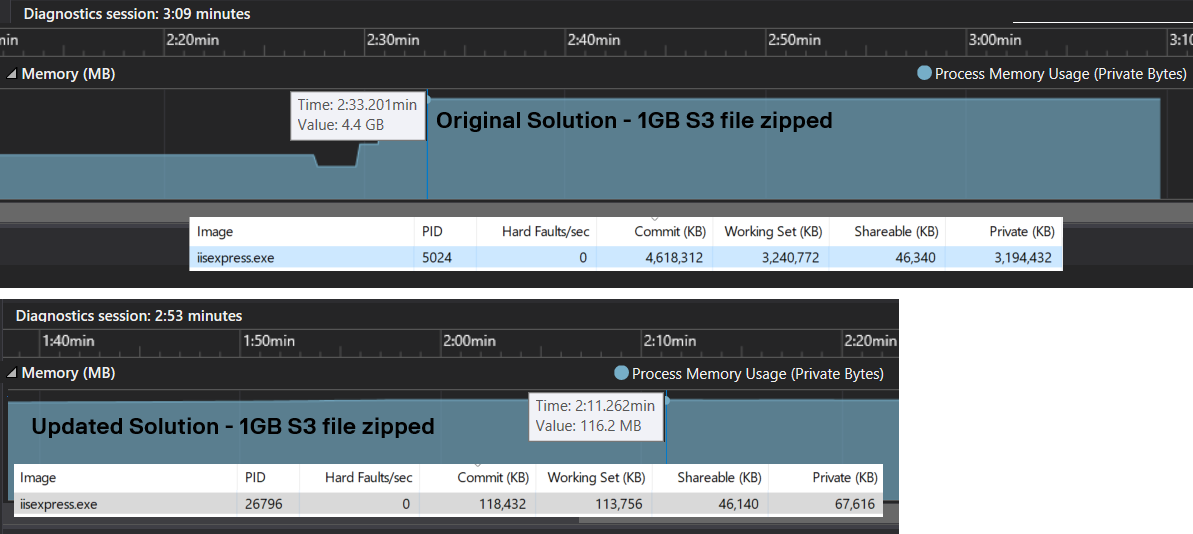
Benchmarking the two solutions
The download time is similar.
But the difference in memory usage is startling for zipping a single 1 GB file compared to the original solution, 4.4GB vs 116 MB.